Mapping Parameters :-
------------------------
Parameter are used to minimize hard coding in ETL as it avoids changing values in ETL. Mapping parameters are values which remain constant through out the entire session. We will give the mapping parameters values in parameter file.
After we create parameter or variables it appears in expression editor, we can use it in any expression of the mapping. Before we run a session, we define parameter value in a parameter file for the session, here we use any constant value. If the parameter is not defined in parameter file, the integration service uses user defined value as parameter. If the initial value is not defined, the Integration Service uses a default value based on the datatype of the mapping parameter.
Parameter file contains two sections:-
------------------------------------
Header section / Global variables:
It is to identify integration service, folder, workflow, worklet, session to which parameter and variables apply
Definition section / Local variables :
It contains list of parameters and variables with their assigned values.
So lets create a simple mapping that loads source data to target table and pass the value to the parameter file.

Now we give condition in source qualifier as Source EMP1.DEPTNO=$$DEPTNO.

Now create a parameter file for the mapping

Now we have to give parameter file location.
Go to the mappings tab and in the left, we find an option as ' files, directories and commands', so click on that.A new screen appears, under 'parameter filename option' give the path of this parameter file including the file name.

So lets us execute workflow and see the output
Mapping variables :-
---------------------
Mapping variables are basically used for incremental load or to read the source. If your source table contains timestamp transactions and if you want to evaluation transaction on a daily basis we use mapping variables.

Mapping variables are values that can change between sessions.
Integration Service saves the latest value of a mapping variable to the repository at the end of each successful session.
The Integration Service holds two different values for a mapping variable during a session run:
- Start value of a mapping variable
- Current value of a mapping variable
Start Value :-
------------
The start value is the value of the variable at the start of the session. The start value could be a value defined in the parameter file for the variable, a value
assigned in the pre-session variable assignment, a value saved in the repository from the previous run of the session, a user defined initial value for the
variable, or the default value based on the variable datatype. The Integration Service looks for the start value in the following order:
- Value in parameter file
- Value in pre-session variable assignment
- Value saved in the repository
- Initial value
- Datatype default value
For example, you create a mapping variable in a mapping or mapplet and enter an initial value, but you do not define a value for the variable in a parameter file. The first time the Integration Service runs the session, it evaluates the start value of the variable to the configured initial value. The next time the session runs, the Integration Service evaluates the start value of the variable to the value saved in the repository. If you want to override the value saved in the repository before running a session, you need to define a value for the variable in a parameter file. When you define a mapping variable in the parameter file, the Integration Service uses this value instead of the value saved in the repository or the configured initial value for the variable.
When you use a mapping variable ('$$MAPVAR') in an expression, the expression always returns the start value of the mapping variable. If the start value of MAPVAR is 0, then $$MAPVAR returns 0. To return the current value of the mapping variable, use the following expression: SETVARIABLE($$MAPVAR, NULL).
Current Value :-
--------------
The current value is the value of the variable as the session progresses. When a session starts, the current value of a variable is the same as the start value. As the session progresses, the Integration Service calculates the current value using a variable function that you set for the variable. Unlike the start value of a mapping variable, the current value can change as the Integration Service evaluates the current value of a variable as each row passes through the mapping. The final current value for a variable is saved to the repository at the end of a successful session. When a session fails to complete, the Integration Service does not update the value of the variable in the repository. The Integration Service states the value saved to the repository for each mapping variable in the session log.
If a variable function is not used to calculate the current value of a mapping variable, the start value of the variable is saved to the repository.
The transformation language provides the following variable functions to use in a mapping:
- SetMaxVariable
- SetMinVariable
- SetCountVariable
- SetVariable.
The order in which the Integration Service encounters variable functions in the mapping may not be the same for every session run. This may cause inconsistent results when you use the same variable function multiple times in a mapping.
The Integration Service does not save the final current value of a mapping variable to the repository when any of the following conditions are true:
The session fails to complete.
The session is configured for a test load.
The session is a debug session.
The session runs in debug mode and is configured to discard session output.
In order to create Mapping variable, go to mappings tab and select ' parameters and variables' option. Add mapping variable here

Now we give condition in source qualifier as Source EMP1.DEPTNO> $$DATE

We define mapping variable in expression editor of expression transformation like this image

After executing the workflow, it will load variables in $$date.
Each and every time we execute workflow new variable is replace in the place of $$date. As a result we get a persistent value as in the image

So with the help of mapping variables we can perform incremental loads.
We can refresh persistent values if we want to load data from starting
------------------------
Parameter are used to minimize hard coding in ETL as it avoids changing values in ETL. Mapping parameters are values which remain constant through out the entire session. We will give the mapping parameters values in parameter file.
After we create parameter or variables it appears in expression editor, we can use it in any expression of the mapping. Before we run a session, we define parameter value in a parameter file for the session, here we use any constant value. If the parameter is not defined in parameter file, the integration service uses user defined value as parameter. If the initial value is not defined, the Integration Service uses a default value based on the datatype of the mapping parameter.
Parameter file contains two sections:-
------------------------------------
Header section / Global variables:
It is to identify integration service, folder, workflow, worklet, session to which parameter and variables apply
Definition section / Local variables :
It contains list of parameters and variables with their assigned values.
So lets create a simple mapping that loads source data to target table and pass the value to the parameter file.
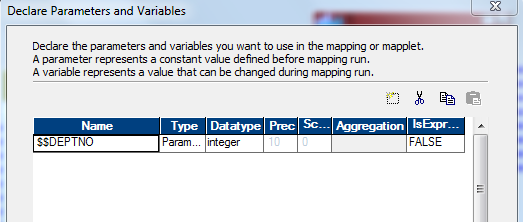

Now create a parameter file for the mapping

Now we have to give parameter file location.
Go to the mappings tab and in the left, we find an option as ' files, directories and commands', so click on that.A new screen appears, under 'parameter filename option' give the path of this parameter file including the file name.

So lets us execute workflow and see the output
Mapping variables :-
---------------------
Mapping variables are basically used for incremental load or to read the source. If your source table contains timestamp transactions and if you want to evaluation transaction on a daily basis we use mapping variables.
Mapping variables are values that can change between sessions.
Integration Service saves the latest value of a mapping variable to the repository at the end of each successful session.
The Integration Service holds two different values for a mapping variable during a session run:
- Start value of a mapping variable
- Current value of a mapping variable
Start Value :-
------------
The start value is the value of the variable at the start of the session. The start value could be a value defined in the parameter file for the variable, a value
assigned in the pre-session variable assignment, a value saved in the repository from the previous run of the session, a user defined initial value for the
variable, or the default value based on the variable datatype. The Integration Service looks for the start value in the following order:
- Value in parameter file
- Value in pre-session variable assignment
- Value saved in the repository
- Initial value
- Datatype default value
For example, you create a mapping variable in a mapping or mapplet and enter an initial value, but you do not define a value for the variable in a parameter file. The first time the Integration Service runs the session, it evaluates the start value of the variable to the configured initial value. The next time the session runs, the Integration Service evaluates the start value of the variable to the value saved in the repository. If you want to override the value saved in the repository before running a session, you need to define a value for the variable in a parameter file. When you define a mapping variable in the parameter file, the Integration Service uses this value instead of the value saved in the repository or the configured initial value for the variable.
When you use a mapping variable ('$$MAPVAR') in an expression, the expression always returns the start value of the mapping variable. If the start value of MAPVAR is 0, then $$MAPVAR returns 0. To return the current value of the mapping variable, use the following expression: SETVARIABLE($$MAPVAR, NULL).
Current Value :-
--------------
The current value is the value of the variable as the session progresses. When a session starts, the current value of a variable is the same as the start value. As the session progresses, the Integration Service calculates the current value using a variable function that you set for the variable. Unlike the start value of a mapping variable, the current value can change as the Integration Service evaluates the current value of a variable as each row passes through the mapping. The final current value for a variable is saved to the repository at the end of a successful session. When a session fails to complete, the Integration Service does not update the value of the variable in the repository. The Integration Service states the value saved to the repository for each mapping variable in the session log.
If a variable function is not used to calculate the current value of a mapping variable, the start value of the variable is saved to the repository.
The transformation language provides the following variable functions to use in a mapping:
- SetMaxVariable
- SetMinVariable
- SetCountVariable
- SetVariable.
The order in which the Integration Service encounters variable functions in the mapping may not be the same for every session run. This may cause inconsistent results when you use the same variable function multiple times in a mapping.
The Integration Service does not save the final current value of a mapping variable to the repository when any of the following conditions are true:
The session fails to complete.
The session is configured for a test load.
The session is a debug session.
The session runs in debug mode and is configured to discard session output.
In order to create Mapping variable, go to mappings tab and select ' parameters and variables' option. Add mapping variable here


We define mapping variable in expression editor of expression transformation like this image

After executing the workflow, it will load variables in $$date.
Each and every time we execute workflow new variable is replace in the place of $$date. As a result we get a persistent value as in the image

So with the help of mapping variables we can perform incremental loads.
We can refresh persistent values if we want to load data from starting










{kind=link}