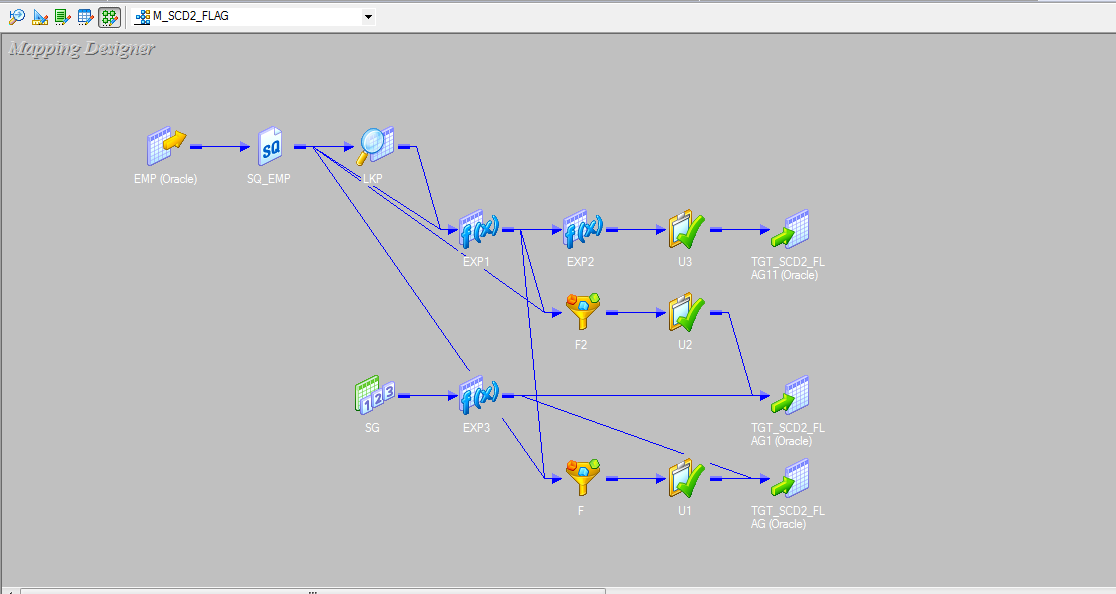
List of Filters in Unix:-
-----------------------
$HEAD
$TAIL
$NL
$CUT
$PASTE
$SORT
$TR
$TEE
$SED
$GREP
$FGREP
$EGREP
$HEAD :- (These are line filters)
--------
Head filename : It always displays first 10 lines from a file
Head -3 file1 : It displays first 3 lines.
Head -5 file1 : It displays first 5 lines.
Head -5v file1 : It displays first 5 lines along with the filename (here v indicates verbose).
Head -5 file1 file2 : It displays first 5 lines from both the files along with the filenames.
$TAIL :- (These are line filters)
-------
Tail filename : It always displays last 10 lines from a file
Tail -3 file1 : It displays last 3 lines.
Tail -5 file1 : It displays last 5 lines.
Tail -5v file1 : It displays last 5 lines along with the filename (here v indicates verbose).
Tail -5 file1 file2 :
Head -5 file1 | Tail -1 file1 : It displays first 5 lines and then displays last line from the result of 5.
NL :- (Number lines of files)
------
Nl file1 : It displays line numbers in file1
Nl file1 > file2 : It redirects all the file1 information to file2.
CUT :- (It removes sections from each line of files)
------
Cut -d ',' -f 3 file1 : It displays only the 3rd field from the file1 (complete 3rd column is display). For delimiter separated fields, the -d option is used.
Cut -d ' ' -f 3 file1 : It displays only the 3rd field from the file1 (complete 3rd column is display). The default delimiter is the tab character.
Cut -d ',' -f 2,3 file1 : It displays only the 2nd and 3rd field from the file1 (complete 2nd and 3rd column is display).
Cut -d ',' -f 1,3 file1 : It displays only the 1st and 3rd field from the file1 (complete 1st and 3rd column is display).
Cut -d ' ' -f 1-3 file1 : It displays from 1st to 3rd field from the file1 (complete 1st to 3rd column is display).
Cut -c1,7 file1 : It displays first character and 7th character.
Cut -c1-7 file1 : It displays from first character to 7th character.
PASTE :- (It merges lines of files)
--------
Paste file1 file2 : It merges two files or it display both files side by side.
Paste -s file1 file2 : It merges two files or it display both files one by one.
SORT :-
-------
Sort file1 : It sorts fields from the file1.
Sort -r file1 : It sorts fields from the file1 in the reverse order.
Sort -n file1 : It sorts fields from the file1 in the numerical order, if the numeric data exits.
Sort -rn file1 : It sorts fields from the file1 in the numerical reverse order, if the numeric data exits.
Sort -ofile2 file1 : It sorts and outputs the fields of file1 in file2.
TR :- (Translate or delete characters)
-----
Tr 's' 'n' < file1 : It converts character S to N, where s is present from the file1.
Tr 'a-z' 'A-Z' < file1 : It converts all the small characters into Capital letters.
Tr 'aeiou' 'AEIOU' < file1 : It converts all the small letters vowels into capital letters vowels.
TEE :- (It reads from standard input and writes to standard output)
-----
Cal | Tee file1 : It takes input from cal and redirects to file1.
Wc -l file1.txt| tee file2.txt
SED :-
------
(Sed command or Stream Editor is very powerful utility offered by Linux/Unix systems. It is mainly used for text substitution , find & replace but it can also perform other text manipulations like insertion, deletion, search etc. With SED, we can edit complete files without actually having to open it.)
Sed 2q file1 : It filters and displays only first two lines.
Sed -n 2p file1 : It filters and displays only second line from file1.
Sed -n -e 2p -e 5p file1 : It filters and displays only second line and 5th line from file1.
Sed 4d fruits : '4’ is the line number & option ‘d’ will delete the mentioned line number.
Sed 3d fruits > newfile : '3’ is the line number & option ‘d’ will delete the mentioned line number and result will be display in newfile.
GREP :- (Globally search for regular expressions)
-------
Grep Apple File1 : It displays lines with apple from the file1.
Grep column_name File1 : It displays column_name from the file1.
Grep -n column_name File1 : It displays number for column_name from the file1.
FGREP :- (Fast Globally search for regular expressions)
-------
EGREP :- (Extended Globally search for regular expressions)
-------
-----------------------
$HEAD
$TAIL
$NL
$CUT
$PASTE
$SORT
$TR
$TEE
$SED
$GREP
$FGREP
$EGREP
$HEAD :- (These are line filters)
--------
Head filename : It always displays first 10 lines from a file
Head -3 file1 : It displays first 3 lines.
Head -5 file1 : It displays first 5 lines.
Head -5v file1 : It displays first 5 lines along with the filename (here v indicates verbose).
Head -5 file1 file2 : It displays first 5 lines from both the files along with the filenames.
$TAIL :- (These are line filters)
-------
Tail filename : It always displays last 10 lines from a file
Tail -3 file1 : It displays last 3 lines.
Tail -5 file1 : It displays last 5 lines.
Tail -5v file1 : It displays last 5 lines along with the filename (here v indicates verbose).
Tail -5 file1 file2 :
Head -5 file1 | Tail -1 file1 : It displays first 5 lines and then displays last line from the result of 5.
NL :- (Number lines of files)
------
Nl file1 : It displays line numbers in file1
Nl file1 > file2 : It redirects all the file1 information to file2.
CUT :- (It removes sections from each line of files)
------
Cut -d ',' -f 3 file1 : It displays only the 3rd field from the file1 (complete 3rd column is display). For delimiter separated fields, the -d option is used.
Cut -d ' ' -f 3 file1 : It displays only the 3rd field from the file1 (complete 3rd column is display). The default delimiter is the tab character.
Cut -d ',' -f 2,3 file1 : It displays only the 2nd and 3rd field from the file1 (complete 2nd and 3rd column is display).
Cut -d ',' -f 1,3 file1 : It displays only the 1st and 3rd field from the file1 (complete 1st and 3rd column is display).
Cut -d ' ' -f 1-3 file1 : It displays from 1st to 3rd field from the file1 (complete 1st to 3rd column is display).
Cut -c1,7 file1 : It displays first character and 7th character.
Cut -c1-7 file1 : It displays from first character to 7th character.
PASTE :- (It merges lines of files)
--------
Paste file1 file2 : It merges two files or it display both files side by side.
Paste -s file1 file2 : It merges two files or it display both files one by one.
SORT :-
-------
Sort file1 : It sorts fields from the file1.
Sort -r file1 : It sorts fields from the file1 in the reverse order.
Sort -n file1 : It sorts fields from the file1 in the numerical order, if the numeric data exits.
Sort -rn file1 : It sorts fields from the file1 in the numerical reverse order, if the numeric data exits.
Sort -ofile2 file1 : It sorts and outputs the fields of file1 in file2.
TR :- (Translate or delete characters)
-----
Tr 's' 'n' < file1 : It converts character S to N, where s is present from the file1.
Tr 'a-z' 'A-Z' < file1 : It converts all the small characters into Capital letters.
Tr 'aeiou' 'AEIOU' < file1 : It converts all the small letters vowels into capital letters vowels.
TEE :- (It reads from standard input and writes to standard output)
-----
Cal | Tee file1 : It takes input from cal and redirects to file1.
Wc -l file1.txt| tee file2.txt
SED :-
------
(Sed command or Stream Editor is very powerful utility offered by Linux/Unix systems. It is mainly used for text substitution , find & replace but it can also perform other text manipulations like insertion, deletion, search etc. With SED, we can edit complete files without actually having to open it.)
Sed 2q file1 : It filters and displays only first two lines.
Sed -n 2p file1 : It filters and displays only second line from file1.
Sed -n -e 2p -e 5p file1 : It filters and displays only second line and 5th line from file1.
Sed 4d fruits : '4’ is the line number & option ‘d’ will delete the mentioned line number.
Sed 3d fruits > newfile : '3’ is the line number & option ‘d’ will delete the mentioned line number and result will be display in newfile.
GREP :- (Globally search for regular expressions)
-------
Grep Apple File1 : It displays lines with apple from the file1.
Grep column_name File1 : It displays column_name from the file1.
Grep -n column_name File1 : It displays number for column_name from the file1.
FGREP :- (Fast Globally search for regular expressions)
-------
EGREP :- (Extended Globally search for regular expressions)
-------