SCD Type 2 Flag is the method used to store historical data is maintained along with current data.
- Create a mapping and name it.
- Drag Emp source into the mapping area.
- Create a Lookup transformation on target table.
- On Primary key columns you should define your condition, because its the matching column between source and target.

- Create an Expression, drag the ports from lookup transformation and name as prev record. This tells us that records are old ones which are used to compare with new ones.
- Drag the comparision keys from source qualifier to Expression
- Create two ports as Newflag and Changedflag and give syntax as Isnull (Cust_key) and Not Isnull(Cust_key) and (Prev_Empn != Empno OR Prev_Ename != Ename OR Prev_Sal != Sal)


- First syntax will check for nulls. If there are null, lookup will insert data into the target table.
- Second syntax will check for existing rows. If there are rows, lookup will update data into the target table.
- Create Filter1 and drag all the ports from source qualifier and give filter condition as NEWFLAG
- Connect update strategy and give the 'Update Strategy Expression' as DD_INSERT


- Create Filter2 and drag Cust key and comparision keys from source and give filter condition as CHANGEFLAG
- Connect update strategy and give the 'Update Strategy Expression' as DD_INSERT
- Create Sequence gen, connect it to Expression and connect the NEXTVAL port to CUST_KEY ports in both Target instances 1 & 2
- Also create FLAG port, assign value 1 to it and connect port to both Target instances 1 & 2
- Create another Expression, drag CUST_KEY to it from Filter2 and create FLAG port, Give the value as 0.
- Create a new update strategy and give the 'Update Strategy Expression' as DD_UPDATE
- Make three instances of target, Connect update strategy 1 to target 1 and update strategy 2 to target 2, Connect update strategy 3 to target 3
- Here First pipeline inserts new data into the target, Second pipeline inserts changed data into the target where as Third pipeline updates changed data into the target. Connect only that ports which you want to insert and update in the target table
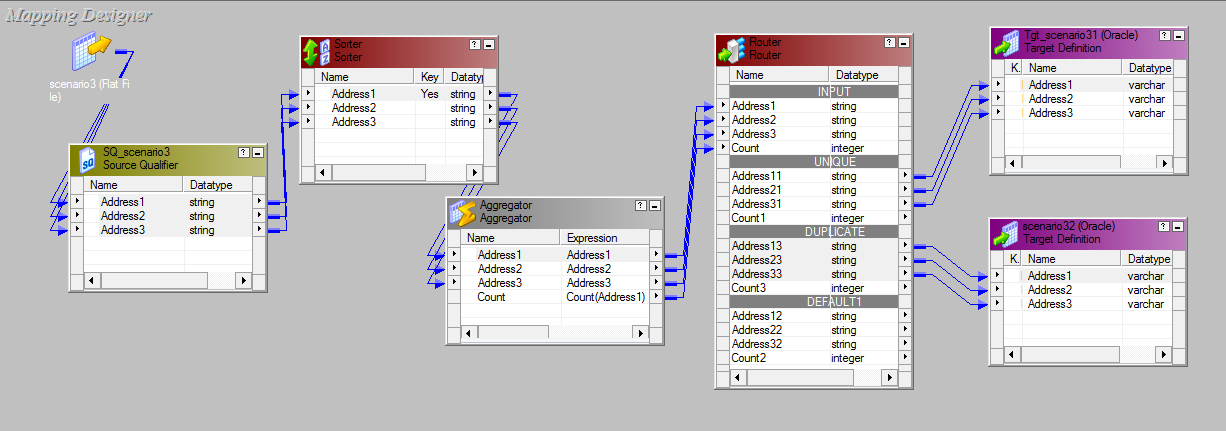
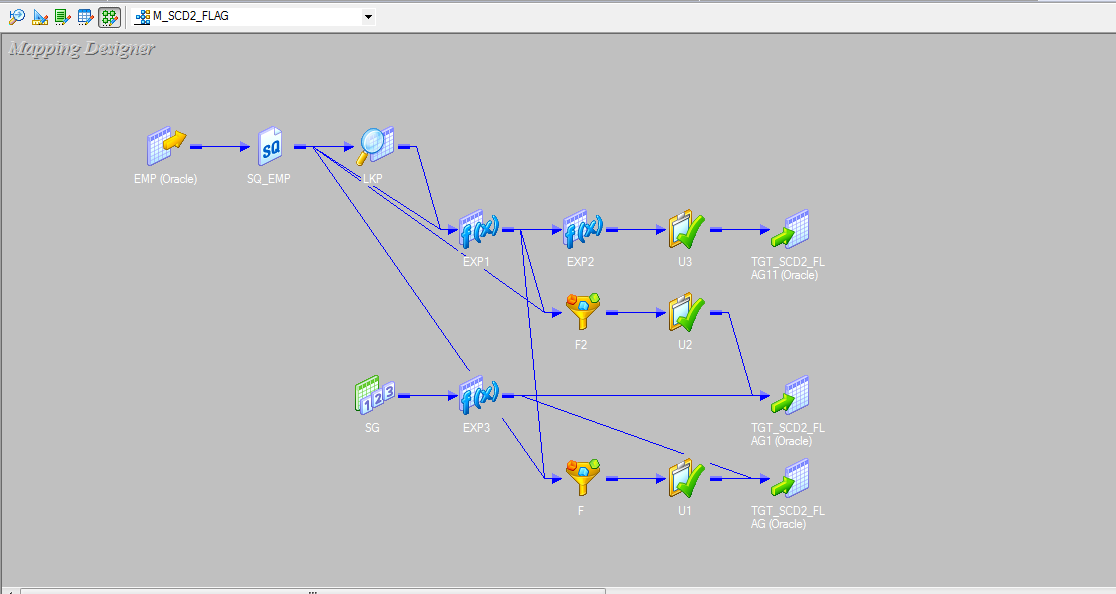
- Final mapping looks like below screen shot


Note 1 : Lookup condition should be on logical key column
Note 2 : lookup transformation should contain Logical key, Primary key & Comparison key columns.
Note 3 : Second pipeline in the mapping contains comparison key, primary key & changed flag columns.
Note 4 : Expression transformation should contain only primary key, comparision keys along with related source keys and new and changed flag.
- Create a mapping and name it.
- Drag Emp source into the mapping area.
- Create a Lookup transformation on target table.
- On Primary key columns you should define your condition, because its the matching column between source and target.

- Create an Expression, drag the ports from lookup transformation and name as prev record. This tells us that records are old ones which are used to compare with new ones.
- Drag the comparision keys from source qualifier to Expression
- Create two ports as Newflag and Changedflag and give syntax as Isnull (Cust_key) and Not Isnull(Cust_key) and (Prev_Empn != Empno OR Prev_Ename != Ename OR Prev_Sal != Sal)


- First syntax will check for nulls. If there are null, lookup will insert data into the target table.
- Second syntax will check for existing rows. If there are rows, lookup will update data into the target table.
- Create Filter1 and drag all the ports from source qualifier and give filter condition as NEWFLAG
- Connect update strategy and give the 'Update Strategy Expression' as DD_INSERT


- Create Filter2 and drag Cust key and comparision keys from source and give filter condition as CHANGEFLAG
- Connect update strategy and give the 'Update Strategy Expression' as DD_INSERT
- Create Sequence gen, connect it to Expression and connect the NEXTVAL port to CUST_KEY ports in both Target instances 1 & 2
- Also create FLAG port, assign value 1 to it and connect port to both Target instances 1 & 2
- Create another Expression, drag CUST_KEY to it from Filter2 and create FLAG port, Give the value as 0.
- Create a new update strategy and give the 'Update Strategy Expression' as DD_UPDATE
- Make three instances of target, Connect update strategy 1 to target 1 and update strategy 2 to target 2, Connect update strategy 3 to target 3
- Here First pipeline inserts new data into the target, Second pipeline inserts changed data into the target where as Third pipeline updates changed data into the target. Connect only that ports which you want to insert and update in the target table
- Final mapping looks like below screen shot


Note 1 : Lookup condition should be on logical key column
Note 2 : lookup transformation should contain Logical key, Primary key & Comparison key columns.
Note 3 : Second pipeline in the mapping contains comparison key, primary key & changed flag columns.
Note 4 : Expression transformation should contain only primary key, comparision keys along with related source keys and new and changed flag.