Workflow variables :-
----------------------
Workflow variables provides ability to store data, in order to use it in the conditions and actions within workflow. If we want to store the variable values or numbers and to track number of times the session triggered we use workflow variables.
Series of sessions which are dependent on each other in an order is called Sequential batch
Series of sessions which are not dependent on each other and connected individually to start task is called Parallel batch.
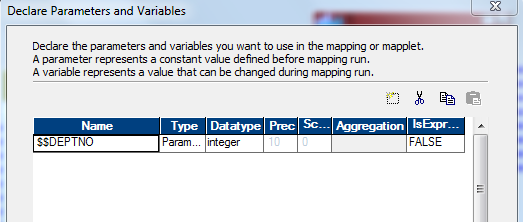
In order to create workflow variable we go to workflow tab and edit it. We select variable tab and add the variables there.

To use work flow variable an assignment task is created and it is used to assign variables to the other sessions.

After assigning variable Next we give link condition so that next session triggers only after satisfying the condition.
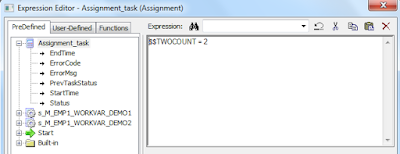
Final Workflow looks like this


----------------------
Workflow variables provides ability to store data, in order to use it in the conditions and actions within workflow. If we want to store the variable values or numbers and to track number of times the session triggered we use workflow variables.
Series of sessions which are dependent on each other in an order is called Sequential batch
Series of sessions which are not dependent on each other and connected individually to start task is called Parallel batch.
In order to create workflow variable we go to workflow tab and edit it. We select variable tab and add the variables there.

To use work flow variable an assignment task is created and it is used to assign variables to the other sessions.

After assigning variable Next we give link condition so that next session triggers only after satisfying the condition.
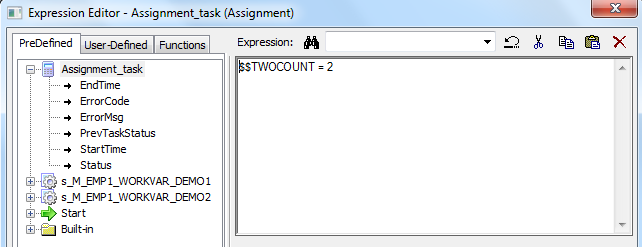
Final Workflow looks like this




















{kind=link}