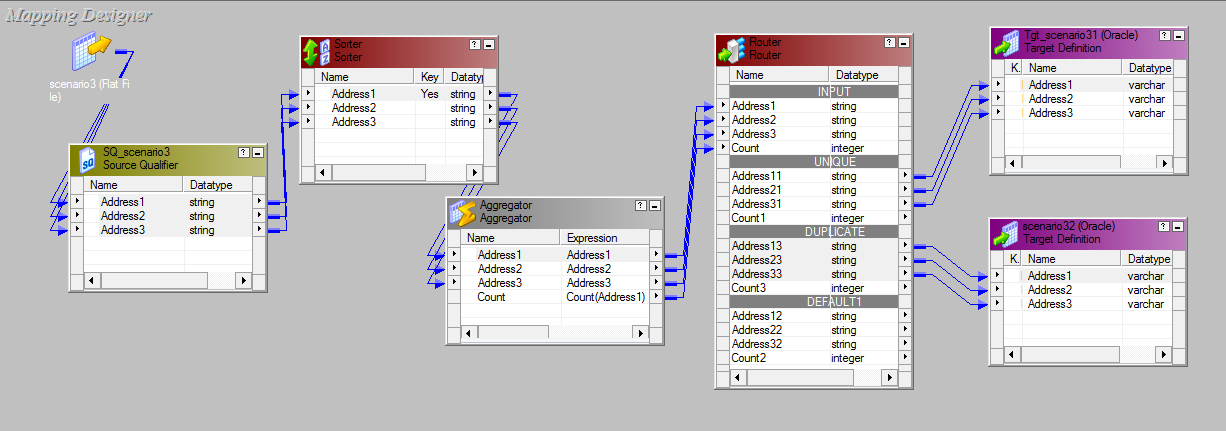
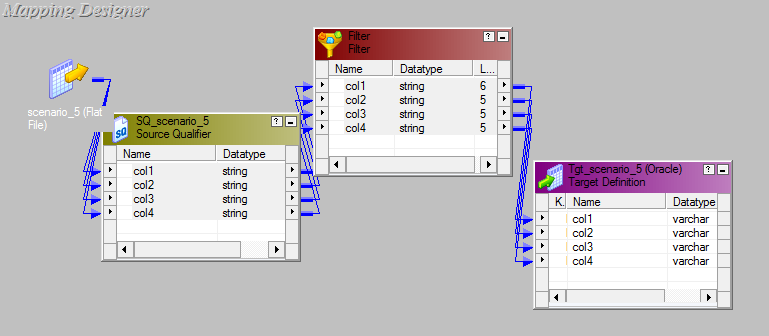
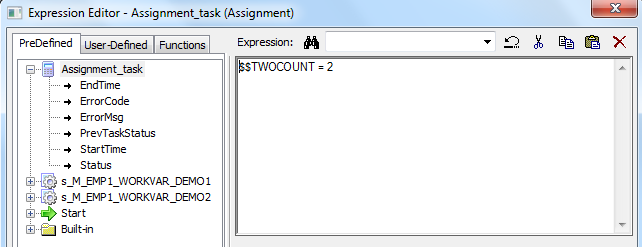
Mapplet :-

- Apply the mapping logic between input and output Mapplet.

- Now apply this logic in mapping where ever there is requirement.

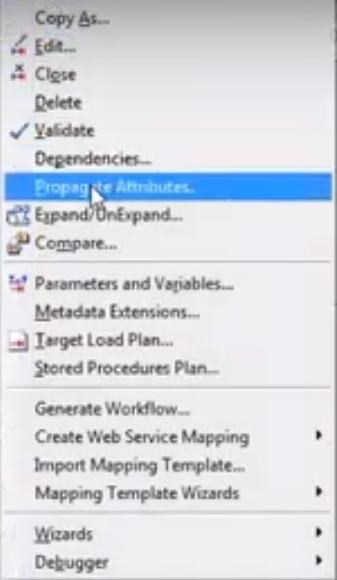
- If you want to show mapplet logic in the mapping just go to mapping click expand/unexpand option. Select correct one from the list of mapplets & click ok.
----------
If you want to create same logic in multiple mapping we use Mapplets. Instead of creating logic every time, we can create it in a single Mapplet and use it in many mappings.
- Go to Mapplet designer, create Mapplet input and output from transformations
- Apply the mapping logic between input and output Mapplet.

- Now apply this logic in mapping where ever there is requirement.

Worklet :-
----------
If you want to create dependencies between the workflows or sessions, we use worklets.
If you have many sessions in a mapping its very difficult to manage with dependencies, instead of adding dependencies among various session we use Worklets to make our work easy by creating dependencies among different Worklets.



We cannot edit it once its converted into reusable. We need to go to Transformation developer to change anything if required. If any transformation is created in Transformation developer it will be by default a reusable transformation

----------
If you want to create dependencies between the workflows or sessions, we use worklets.
If you have many sessions in a mapping its very difficult to manage with dependencies, instead of adding dependencies among various session we use Worklets to make our work easy by creating dependencies among different Worklets.
- Create a worklet, name it and add connect sessions to it.

- Drag worklet from left and connect all of them together in the workflow designer.

Reusable Transformation :-
--------------------------------
If we want to use any transformation again & again in the mapping we can create reusable transformation.
Double click transformation & check option reusable to make it reusable transformation.
We cannot edit it once its converted into reusable. We need to go to Transformation developer to change anything if required. If any transformation is created in Transformation developer it will be by default a reusable transformation