It's used for parallel processing in order to decrease the time to load data into target. Different partitions are pass through, round robin, hash user key, auto user key, key range and finally database partition.
Each type of partition works according to its own logic.
- Partitioning option is found in session, click on mapping and you can find an option in bottom left, beside transformation option as 'Partitions', Click on it.

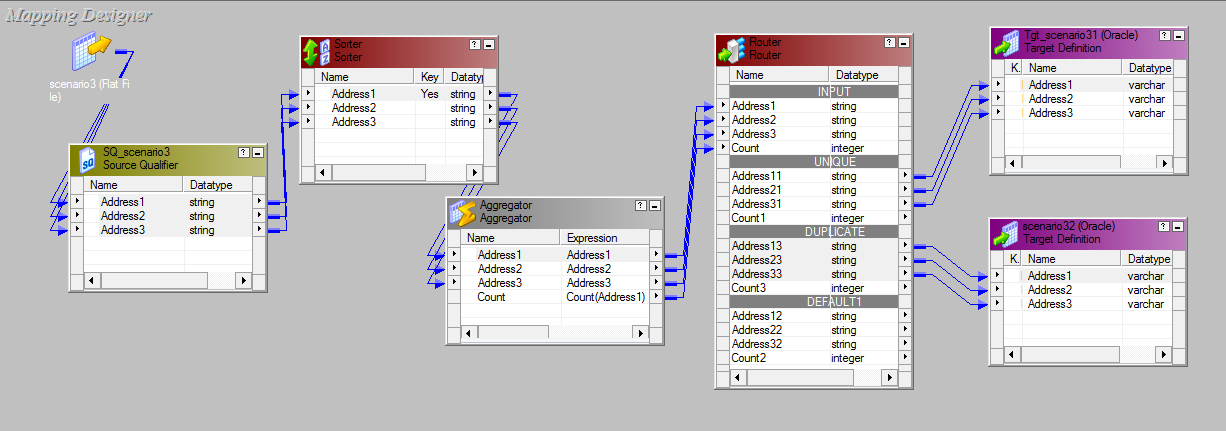
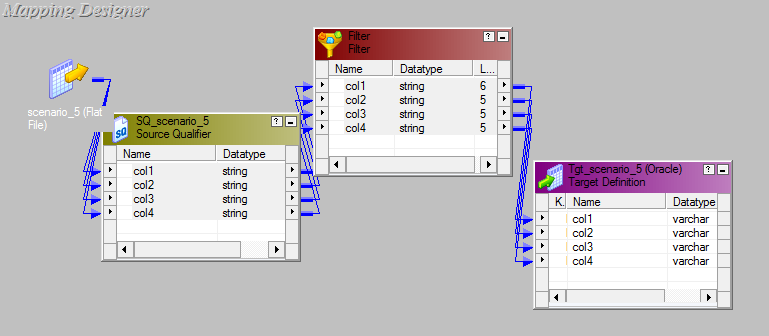
- Look of mapping after we develop a mapping code

Pass through : Its default partition. It distributes the rows sequentially to all the partitions. The Integration Service processes data without redistributing rows
among partitions. All rows in a single partition stay in the partition after crossing a pass-through partition point. Choose pass-through partitioning when we want to create an additional pipeline stage to improve performance, but do not want to change the distribution of data across partitions.

Round robin : The Integration Service distributes data evenly among all partitions. Use round-robin partitioning where we want each partition to process approximately the same numbers of rows i.e. load balancing.

Hash Auto-key : It generates a hash key value by which it distributes rows according to its hash key logic to the partitions.The Integration Service uses a hash function to group rows of data among partitions. The Integration Service groups the data based on a partition key.The Integration Service uses all grouped or sorted ports as a compound partition key. We may need to use hash auto-keys partitioning at Rank, Sorter and unsorted Aggregator transformations.
Hash userkey : The Integration Service uses a hash function to group rows of data among partitions. We define the number of ports to generate the partition key.

Key range : We need to give the key range like which partition should process how many rows. Its completely according to our logic. The Integration Service
distributes rows of data based on a port or set of ports that we define as the partition key. For each port, we define a range of values. The Integration Service uses the key and ranges to send rows to the appropriate partition. Use key range partitioning when the sources or targets in the pipeline are partitioned by key range.


Database : It automatically checks the database like how many partitions are available and based on the it distributes rows to the partitions.The Integration
Service queries the database system for table partition information. It reads partitioned data from the corresponding nodes in the database.
Points to consider while using Informatica partitions :-
-----------------------------------------------------------
* We cannot specify partition for Sequence generator.
* We should specify sorter before joiner otherwise the session fails.
* We cannot create a partition key for hash auto-keys, round-robin, or pass-through types partitioning.
* If you have bitmap index defined upon the target and you are using pass-through partitioning to, say Update the target table - the session might fail as bitmap index creates serious locking problem in this scenario.
* Partitioning considerably increases the total DTM buffer memory requirement for the job. Ensure you have enough free memory in order to avoid memory allocation failures.
* When you do pass-through partitioning, Informatica will try to establish multiple connection requests to the database server. Ensure that database is configured to accept high number of connection requests.
* As an alternative to partitioning, you may also use native database options to increase degree of parallelism of query processing. For example in Oracle database you can either specify PARALLEL hint or alter the DOP of the table in subject.
* If required you can even combine Informatica partitioning with native database level parallel options - e.g. you create 5 pass-through pipelines, each sending query to Oracle database with PARALLEL hint.
Default Partitions are SourceQualifier, Aggregator, Target.
SQ : Pass though
Sorter : Hash Auto key
Router :
Lookup : Any partition
Expression : Pass through
Aggregator : Hash Auto key
Sorter : Pass through
Target : Round robin or Pass through
Joiner : 1:n Its has a different logic of partitiong.
Each type of partition works according to its own logic.
- Partitioning option is found in session, click on mapping and you can find an option in bottom left, beside transformation option as 'Partitions', Click on it.

- Look of mapping after we develop a mapping code

Pass through : Its default partition. It distributes the rows sequentially to all the partitions. The Integration Service processes data without redistributing rows
among partitions. All rows in a single partition stay in the partition after crossing a pass-through partition point. Choose pass-through partitioning when we want to create an additional pipeline stage to improve performance, but do not want to change the distribution of data across partitions.

Round robin : The Integration Service distributes data evenly among all partitions. Use round-robin partitioning where we want each partition to process approximately the same numbers of rows i.e. load balancing.

Hash Auto-key : It generates a hash key value by which it distributes rows according to its hash key logic to the partitions.The Integration Service uses a hash function to group rows of data among partitions. The Integration Service groups the data based on a partition key.The Integration Service uses all grouped or sorted ports as a compound partition key. We may need to use hash auto-keys partitioning at Rank, Sorter and unsorted Aggregator transformations.
Hash userkey : The Integration Service uses a hash function to group rows of data among partitions. We define the number of ports to generate the partition key.

Key range : We need to give the key range like which partition should process how many rows. Its completely according to our logic. The Integration Service
distributes rows of data based on a port or set of ports that we define as the partition key. For each port, we define a range of values. The Integration Service uses the key and ranges to send rows to the appropriate partition. Use key range partitioning when the sources or targets in the pipeline are partitioned by key range.

Database : It automatically checks the database like how many partitions are available and based on the it distributes rows to the partitions.The Integration
Service queries the database system for table partition information. It reads partitioned data from the corresponding nodes in the database.
Points to consider while using Informatica partitions :-
-----------------------------------------------------------
* We cannot specify partition for Sequence generator.
* We should specify sorter before joiner otherwise the session fails.
* We cannot create a partition key for hash auto-keys, round-robin, or pass-through types partitioning.
* If you have bitmap index defined upon the target and you are using pass-through partitioning to, say Update the target table - the session might fail as bitmap index creates serious locking problem in this scenario.
* Partitioning considerably increases the total DTM buffer memory requirement for the job. Ensure you have enough free memory in order to avoid memory allocation failures.
* When you do pass-through partitioning, Informatica will try to establish multiple connection requests to the database server. Ensure that database is configured to accept high number of connection requests.
* As an alternative to partitioning, you may also use native database options to increase degree of parallelism of query processing. For example in Oracle database you can either specify PARALLEL hint or alter the DOP of the table in subject.
* If required you can even combine Informatica partitioning with native database level parallel options - e.g. you create 5 pass-through pipelines, each sending query to Oracle database with PARALLEL hint.
Default Partitions are SourceQualifier, Aggregator, Target.
SQ : Pass though
Sorter : Hash Auto key
Router :
Lookup : Any partition
Expression : Pass through
Aggregator : Hash Auto key
Sorter : Pass through
Target : Round robin or Pass through
Joiner : 1:n Its has a different logic of partitiong.



































{kind=link}