1) A flat file is arrived on the server and workflow will be launched using 'PMCMD' command. After some time another flat file arrives. We need to process in same workflow which is currently running.
- Configuring concurrent workflow is the solution for it.
- Go to the workflow menu and click on edit. You have an option here 'configure concurrent execution'.

- Check in the enable option and the configure concurrent execution button gets highlighted, click on it.
- We have two options here as 'allow concurrent execution with same instance name and allow concurrent execution with unique name'.
- Click on the add button to add two instance names and copy and paste the file location along with parameter file name.

- To execute right click in the blank space and select start workflow advanced.
- Select all the instances which you want to execute.

2) Suppose we have employee details with empno, name and salary and so on. next day few new records generated in source. How do you update the target only with the new records ?
- Incremental aggregation is the solution for this.
- Without the aggregator transformation it does not work.
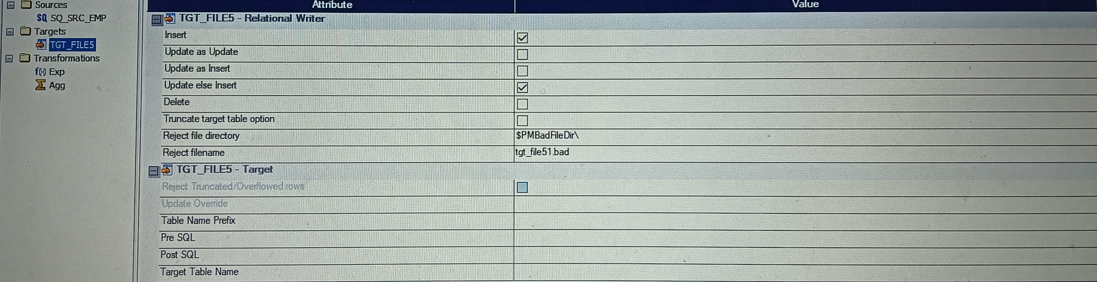
- Primary key must be specified in target.
- For each input record, the Integration Service checks historical information in the index file for a corresponding aggregate group. If it finds a corresponding group, the Integration Service performs the aggregate operation incrementally, using the aggregate data for that group, and saves the incremental change. If it does, the Integration Service creates a new group and saves the record data.

- Source contains all records like empno, ename, salary, flag and so on.
- We give condition in source qualifer editor as ' flag = 'y', as a result only the records with the flag 'y' gets inserted into target.

- In aggregator we generate max, min, sum, avg and check group by port on deptno and connect it to the target.
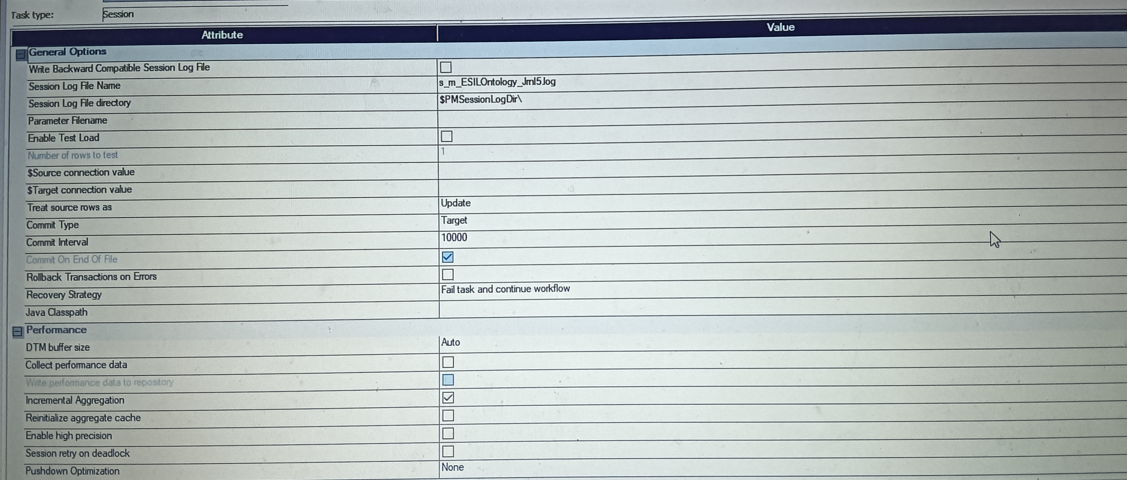
- In session properties check the option 'incremental aggregation' and
- If the we are executing session for the first time check "reinitialize aggregator cache" option.
- Select treat source rows as 'update' and update else insert in session level properties.
- Records 'N' in the source indicate, records that were update in the target.
- Records 'Y' in the source indicate, records that need to be update in the target.
- We can update the target table when ever a new record is inserted.
3) If there are different targets like target 1 & target 2. How do you load target 2 first and target 1 second ?
- Target Load Plan is the solution for it.
- In the mapping tab select 'Target load plan' option and select it.

- Select the target 2 by using up and down arrow keys.

- Now connect source qualifier to target.
4) What is Pushdown Optimization and How do you apply it ?
- Its the technique which converts the Transformation logic into SQL queries and send those statements to database.
- In an actual mapping when we observe session log, we find that integration service selects each and every column and then apply logic according to every transformation one by one. This take much time when we have large amount of data.
- Limitations : It will not support the Rank, Java, Normalizer and transaction control transformation. In this case, we can select either source/target side optimization only.
- Full Pushdown optimization cannot connect to different connections.
- In properties tab of mapping 'Pushdown Optimization' option is available. There are 3 of them, Source, Target and Full Pushdown Optimization.

- We can select source or target or full, to apply SQL query logic.
- In the mapping tab on the left side, select Pushdown optimization option to view the logic how you applied.

- By selecting a new window is opened like below.

- So specify same same connection in target and give target connect name in session level properties as below.
5) There a 3 session in a workflow, 3rd session should trigger only 3rd time when you run the workflow. How do you do it ?
- Create three session from 3 mappings.
- We create a workflow variable to hold the variable value for the session count.

- After assigning variable, create an assignment task to assign the variable to the next session which you want to fail.

- After that, click the link between the assignment task and session task.
- Give the condition as $$THREE_COUNT=3, here we are giving actual condition to the session to execute only on 3rd execution.

- Final workflow looks like this

6) There a 3 session in a workflow, 2nd session should fail but 3rd should execute and workflow should fail. How do you do it ?
- In the 2nd session, check the option fail parent if the task fails.

Points to remember :-
- Target success rows : If this Link condition is satisfied, only then next session will execute other wise, it skips rest of the sessions.
- Source failed rows : If this Link condition is satisfied, only then next session will execute other wise, it skips rest of the sessions.
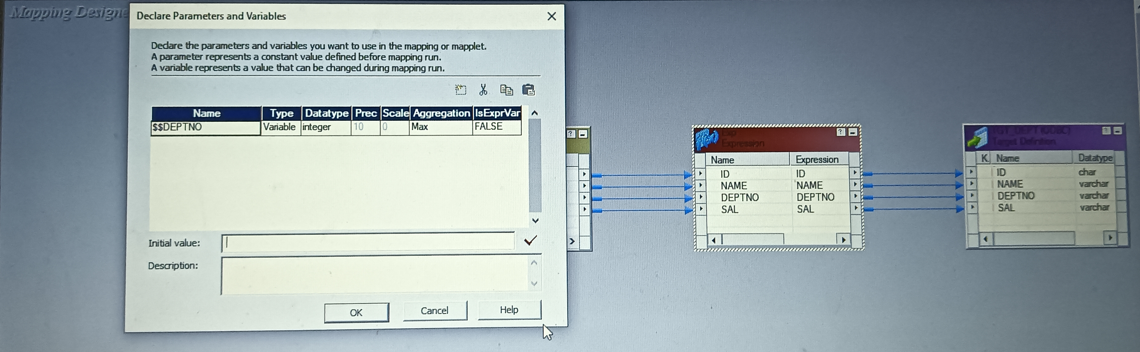
7) How do you assign mapping variables to another mapping ?
- Create mapping1 and assign mapping variables to it as $$DEPTNO1 as per the requirement
- Generate SQL and give condition as Where EMP1.DEPTNO > $$ DEPTNO1
- Create mapping2 and assign mapping variables to it as $$DEPTNO2 as per the requirement
- Generate SQL and give condition as Where EMP1.DEPTNO > $$ DEPTNO2

- Create a workflow and create two session related to mapping1 and mapping2
- Create workflow variable as $$WF_VARIABLE
- In first session, Double click and go to components table

- And in post session variable assignment, assign mapping variable to workflow variable

- In second session, go to components table and in pre session variable assignment, assign workflow variable to second mapping variable

8) How to execute or trigger multiple workflows in sequence in informatica ?

- Now open the session task of the first workflow. In the components tab, add command task in the 'post session success command' option.

- Now execute first workflow, automatically second workflow triggers as per the pmcmd command.

9) If my source contains lakhs of records, if my session stops in between, how do you resume it ?
First of all, if my session stops in between, it will definitely be a fatal error. Fatal errors might cause due to loss of connection, unable to access source or target repository and lack of database space to load data.
If you are using insert and update strategy for your mapping, it does not bother you how much data already been load when it failed.
After restart of workflow it will either insert or update the data in the target table as per business logic implemented.
There are three approaches to do handle this situation.
Approach 1 :
--------------
- You cannot resume session if its failed, you have to restart it, after truncating target table.
Approach 2:
-------------
- If you are sure you have only 50,000 records then set the commit interval 50,000, so the target will be committed only when all the records are loaded
If your target is in a staging environment then do a truncate and load.
This approach demands you to restart the session, therefore do not choose to recover session on fail. The main point here is that since the session failed before the commit, data is not going to be sent to prod tgt table. (Since you have set commit point after...Billion lines...)

Approach 3 : Session configuration for Recovery strategy
--------------
- When you configure a session for recovery, you can recover the session when you recover a workflow, or you can recover the session without running the rest of the workflow.
When you configure a session, you can choose a recovery strategy of fail, restart, or resume: Resume from the last checkpoint. The Integration Service saves the session state of operation and maintains target recovery tables. If the session aborts, stops, or terminates, the Integration Service uses the saved recovery information to resume the session from the point of interruption.

Approach 4 :
--------------
- Perform dynamic lookup on the target, no duplicates will load into the target table.
Approach 5 : Workflow configuration for recovery
--------------- To configure workflow for recovery, we must select workflow for recovery. When this option is enabled, integration service saves the operation in shared location. If workflow fails, it can be recovered.
Enable HA(High availability) recovery option

In the expression transformation, the ports are

Now Pass the output of expression transformation to a router transformation, create one group and specify the condition as Final_occurance=1. Then connect this group to one table. Connect the output of default group to another table.


11) Calculate AVGSAL of the employees
SRC:-

Create Dummy port in Expression & Aggregator

Join both Expression & Aggregator with Joiner using Dummy ports

Now Connect output fields to the target

12) Calculate AVG DEPTSAL of the employees.
In the Aggregator transformation calculate AVG Salary
13) How to implement incremental load in informatica ?
Generate SQL query and give condition as DEPTNO > $$DEPTNO
(OR)
LAST_UPDATED_TIMESTAMP > :$$MAX_TIMESTAMP
- Configuring concurrent workflow is the solution for it.
- Go to the workflow menu and click on edit. You have an option here 'configure concurrent execution'.

- Check in the enable option and the configure concurrent execution button gets highlighted, click on it.
- We have two options here as 'allow concurrent execution with same instance name and allow concurrent execution with unique name'.
- Click on the add button to add two instance names and copy and paste the file location along with parameter file name.

- To execute right click in the blank space and select start workflow advanced.
- Select all the instances which you want to execute.

2) Suppose we have employee details with empno, name and salary and so on. next day few new records generated in source. How do you update the target only with the new records ?
- Incremental aggregation is the solution for this.
- Without the aggregator transformation it does not work.
- Primary key must be specified in target.
- For each input record, the Integration Service checks historical information in the index file for a corresponding aggregate group. If it finds a corresponding group, the Integration Service performs the aggregate operation incrementally, using the aggregate data for that group, and saves the incremental change. If it does, the Integration Service creates a new group and saves the record data.
- We give condition in source qualifer editor as ' flag = 'y', as a result only the records with the flag 'y' gets inserted into target.
- In aggregator we generate max, min, sum, avg and check group by port on deptno and connect it to the target.
- In session properties check the option 'incremental aggregation' and
- If the we are executing session for the first time check "reinitialize aggregator cache" option.
- Select treat source rows as 'update' and update else insert in session level properties.
- Records 'Y' in the source indicate, records that need to be update in the target.
- We can update the target table when ever a new record is inserted.
3) If there are different targets like target 1 & target 2. How do you load target 2 first and target 1 second ?
- Target Load Plan is the solution for it.
- In the mapping tab select 'Target load plan' option and select it.

- Select the target 2 by using up and down arrow keys.

- Now connect source qualifier to target.
4) What is Pushdown Optimization and How do you apply it ?
- Its the technique which converts the Transformation logic into SQL queries and send those statements to database.
- In an actual mapping when we observe session log, we find that integration service selects each and every column and then apply logic according to every transformation one by one. This take much time when we have large amount of data.
- Limitations : It will not support the Rank, Java, Normalizer and transaction control transformation. In this case, we can select either source/target side optimization only.
- Full Pushdown optimization cannot connect to different connections.
- In properties tab of mapping 'Pushdown Optimization' option is available. There are 3 of them, Source, Target and Full Pushdown Optimization.
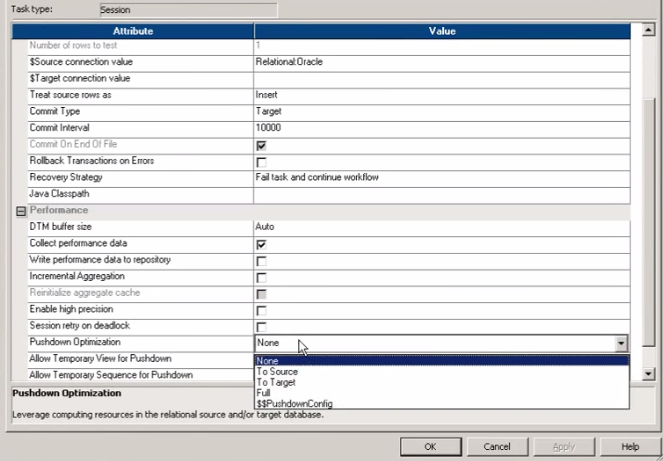
- We can select source or target or full, to apply SQL query logic.
- In the mapping tab on the left side, select Pushdown optimization option to view the logic how you applied.

- By selecting a new window is opened like below.

- So specify same same connection in target and give target connect name in session level properties as below.

5) There a 3 session in a workflow, 3rd session should trigger only 3rd time when you run the workflow. How do you do it ?
- Create three session from 3 mappings.
- We create a workflow variable to hold the variable value for the session count.

- After assigning variable, create an assignment task to assign the variable to the next session which you want to fail.

- After that, click the link between the assignment task and session task.
- Give the condition as $$THREE_COUNT=3, here we are giving actual condition to the session to execute only on 3rd execution.

- Final workflow looks like this

6) There a 3 session in a workflow, 2nd session should fail but 3rd should execute and workflow should fail. How do you do it ?
- In the 2nd session, check the option fail parent if the task fails.

Points to remember :-
- Target success rows : If this Link condition is satisfied, only then next session will execute other wise, it skips rest of the sessions.
- Source failed rows : If this Link condition is satisfied, only then next session will execute other wise, it skips rest of the sessions.
7) How do you assign mapping variables to another mapping ?
- Create mapping1 and assign mapping variables to it as $$DEPTNO1 as per the requirement
- Generate SQL and give condition as Where EMP1.DEPTNO > $$ DEPTNO1
- Create mapping2 and assign mapping variables to it as $$DEPTNO2 as per the requirement
- Generate SQL and give condition as Where EMP1.DEPTNO > $$ DEPTNO2

- Create a workflow and create two session related to mapping1 and mapping2
- Create workflow variable as $$WF_VARIABLE
- In first session, Double click and go to components table

- And in post session variable assignment, assign mapping variable to workflow variable


8) How to execute or trigger multiple workflows in sequence in informatica ?
- Go to task developer and Create a command task
- In the commands tab, add column and enter Pmcmd command, so that second workflow automatically triggers.
- Sample PMCMD command (Pmcmd startworkflow -sv <Integration Service Name> -d <Domain Name> -u <Integration Service Username>
-p <Password> -f <Folder Name> <Workflow>)
- Actual pmcmd command am using is (pmcmd startworkflow -sv Intsvc_tyson
- d Domain_TYSON-PC -u Administrator -p Administrator -f PRACTISE2 WF_EMP_DEMO2)

- Now open the session task of the first workflow. In the components tab, add command task in the 'post session success command' option.

- Now execute first workflow, automatically second workflow triggers as per the pmcmd command.

First of all, if my session stops in between, it will definitely be a fatal error. Fatal errors might cause due to loss of connection, unable to access source or target repository and lack of database space to load data.
If you are using insert and update strategy for your mapping, it does not bother you how much data already been load when it failed.
After restart of workflow it will either insert or update the data in the target table as per business logic implemented.
There are three approaches to do handle this situation.
Approach 1 :
--------------
- You cannot resume session if its failed, you have to restart it, after truncating target table.
Approach 2:
-------------
- If you are sure you have only 50,000 records then set the commit interval 50,000, so the target will be committed only when all the records are loaded
If your target is in a staging environment then do a truncate and load.
This approach demands you to restart the session, therefore do not choose to recover session on fail. The main point here is that since the session failed before the commit, data is not going to be sent to prod tgt table. (Since you have set commit point after...Billion lines...)

Approach 3 : Session configuration for Recovery strategy
--------------
- When you configure a session for recovery, you can recover the session when you recover a workflow, or you can recover the session without running the rest of the workflow.
When you configure a session, you can choose a recovery strategy of fail, restart, or resume: Resume from the last checkpoint. The Integration Service saves the session state of operation and maintains target recovery tables. If the session aborts, stops, or terminates, the Integration Service uses the saved recovery information to resume the session from the point of interruption.

Approach 4 :
--------------
Approach 5 : Workflow configuration for recovery
--------------- To configure workflow for recovery, we must select workflow for recovery. When this option is enabled, integration service saves the operation in shared location. If workflow fails, it can be recovered.
Enable HA(High availability) recovery option
10) Design a mapping to load all unique products in one table and the duplicate rows in another table
In the expression transformation, the ports are
v_prev_ID = v_pres_ID
v_pres_ID = ID
v_occurance = IIF(ID = v_pres_ID, v_occurance+1,1)
Final_occurance = v_occurance
Now Pass the output of expression transformation to a router transformation, create one group and specify the condition as Final_occurance=1. Then connect this group to one table. Connect the output of default group to another table.
- Final mapping looks like below screen shot
11) Calculate AVGSAL of the employees
SRC:-
-------
ID,NAME,LOCATION,SAL
10,ARJUN,HYD,100
10,ARJUN,HYD,100
20,ARUN,PUNE,2000
30,BHASKAR,CHENNAI,3000
100,JOHN,GOA,4000
200,MARTIN,GOA,2000
200,MARTIN,GOA,2000
In the Aggregator transformation calculate AVG Salary
Create Dummy port in Expression & Aggregator
Final mapping looks like below screen shot
12) Calculate AVG DEPTSAL of the employees.
SRC:-
-------
ID,NAME,LOCATION,SAL
10,ARJUN,HYD,10,10000
10,ARJUN,HYD,10,10000
20,ARUN,PUNE,10,10000
30,BHASKAR,CHENNAI,10,10000
40,ALEX,GOA,10,10000
10,JOHN,GOA,20,10000
20,MARTIN,GOA,20,20000
20,MARTIN,GOA,20,20000
In the Aggregator transformation calculate AVG Salary
Group by on DEPT port to get Dept salary based on groups

Create Dummy port in Expression & Aggregator
Join both Expression & Aggregator with Joiner using Dummy ports
Now Connect output fields to the target
Final mapping looks like below screen shot
13) How to implement incremental load in informatica ?
We can implement incremental load by using mapping variables.
In mappings tab, go to parameters and variables & create variable $$DEPTNO
(OR)
$$MAX_TIMESTAMP
(OR)
$$MAX_TIMESTAMP
(OR)
LAST_UPDATED_TIMESTAMP > :$$MAX_TIMESTAMP

Create variable port and assign max variable in order to track latest variable value to perform incremental load
Now Connect output fields to the target
Final mapping looks like below screen shot

Create Rank transformation & Group by on DEPT port


Create aggregator transformation & Group by on DEPT
Create an variable port and use LAST(DEPT) this will get last record from the Top 2 records

Now Connect output fields to the target
Final mapping looks like below screen shot




No comments:
Post a Comment